Redis 数据类型及应用场景
总结redis常用数据类型
redis 特点
- 数据存储在内存中,高速效率高
- 提供丰富的数据类型:string、 hash、 set、 sorted set、bitmap、hyperloglog
- Redis 的所有操作都是原子性的,还支持通过对几个操作合并后的原子性操作,支持事务
- 提供了可靠的备份恢复和集群功能,适用于高并发场景
通常我们都把数据存到关系型数据库中,但为了提升应用的性能,我们应该把访频率高且不会经常变动的数据缓存到内存中。Redis 没有像 MySQL 这类关系型数据库那样强大的查询功能,需要考虑如何把关系型数据库中的数据,合理的对应到缓存的 key-value 数据结构中。
设计 Redis Key
分段设计法
使用冒号把 key 中要表达的多种含义分开表示,步骤如下:
- 把表名转化为 key 前缀
- 主键名(或其他常用于搜索的字段)
- 主键值
- 要存储的字段。
eg. 用户表(user)
| id | name | |
|---|---|---|
| 1 | zj | 156577812@qq.com |
| 2 | ai | 156577813@qq.com |
这个简单的表可能经常会有这个的需求:>根据用户 id 查询用户邮箱地址,可以选择把邮箱地址这个数据存到 redis 中:
1 | set user:id:1:email 156577812@qq.com; |
String数据类型的应用场景
简介
string 类型是 Redis 中最基本的数据类型,最常用的数据类型,甚至被很多玩家当成 redis 唯一的数据类型去使用。string 类型在 redis 中是二进制安全(binary safe)的,这意味着 string 值关心二进制的字符串,不关心具体格式,你可以用它存储 json 格式或 JPEG 图片格式的字符串。
数据模型
string 类型是基本的 Key-Value 结构,Key 是某个数据在 Redis 中的唯一标识,Value 是具体的数据。
| Key | Value |
|---|---|
| ‘name’ | ‘redis’ |
| ‘type’ | ‘string’ |
应用场景
存储 MySQL 中某个字段的值
把 key 设计为 表名:主键名:主键值:字段名
eg.
1 | set user:id:1:email 156577812@qq.com |
存储对象
string 类型支持任何格式的字符串,应用最多的就是存储 json 或其他对象格式化的字符串。(这种场景下推荐使用 hash 数据类型)
1 | set user:id:1 '[{"id":1,"name":"zj","email":"156577812@qq.com"},{"id":1,"name":"zj","email":"156577812@qq.com"}]' |
生成自增 id
当 redis 的 string 类型的值为整数形式时,redis 可以把它当做是整数一样进行自增(incr)自减(decr)操作。由于 redis 所有的操作都是原子性的,所以不必担心多客户端连接时可能出现的事务问题。
hash 数据类型的应用场景
简介
hash 类型很像一个关系型数据库的数据表,hash 的 Key 是一个唯一值,Value 部分是一个 hashmap 的结构。
数据模型
假设有一张数据库表如下:
| id | name | type |
|---|---|---|
| 1 | redis | hash |
如果要用 redis 的 hash 结构存储,数据模型如下:
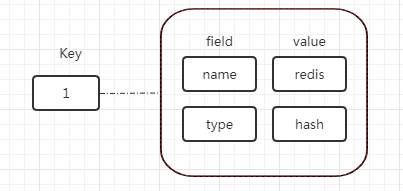
hash 数据类型在存储结构化信息时具有比 string 类型更灵活、更快的优势。具体的说,使用 string 类型存储,必然需要转换和解析 json 格式的字符串。
使用 string 还是 hash
如果在大多数访问中,只使用单个字段,且明确知道哪些字段是可用的,就可以考虑使用 hash 结构。
如果在大多数访问中,使用了大部分字段,就更倾向与使用 string 结构。
应用场景
hash 类型十分适合存储对象类数据,相对于在 string 中介绍的把对象转化为 json 字符串存储,hash 的结构可以任意添加或删除‘字段名’,更加高效灵活。
1 | hmset user:1 name zj email 156577812@qq.com |
list 数据类型的应用场景
简介
list 是按照插入顺序排序的字符串链表,可以在头部和尾部插入新的元素(双向链表实现,两端添加元素的时间复杂度为 O(1))。插入元素时,如果 key 不存在,redis 会为该 key 创建一个新的链表,如果链表中所有的元素都被移除,该 key 也会从 redis 中移除。
数据模型
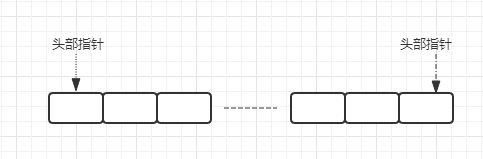
常见操作时用 lpush 命令在 list 头部插入元素, 用 rpop 命令在 list 尾取出数据。
应用场景
消息队列
redis 的 list 数据类型对于大部分使用者来说,是实现队列服务的最经济,最简单的方式。
redis 实现消息队列可以使用 rpush & lpop 或 lpush & rpop,考虑到队列为空时客户端会陷入死循环,可以使用 blpop/brpop 代替 lpop/rpop,blpop/brpop 会使连接阻塞变成闲置连接,闲置久了,服务器会自动断开并跑出异常,客户端要捕获异常并重试。
“最新内容”
因为 list 结构的数据查询两端附近的数据性能非常好,所以适合一些需要获取最新数据的场景,比如新闻类应用的 “最近新闻”。
优化建议
list 是链表结构,所有如果在头部和尾部插入数据,性能会非常高,不受链表长度的影响;但如果在链表中插入数据,性能就会越来越差。
set 数据类型的应用场景
简介
set 数据类型是一个集合(没有排序,不重复),可以对 set 类型的数据进行添加、删除、判断是否存在等操作(时间复杂度是 O(1) )
set 集合不允许数据重复,如果添加的数据在 set 中已经存在,将只保留一份。
set 类型提供了多个 set 之间的聚合运算,如求交集、并集、补集,这些操作在 redis 内部完成,效率很高。
数据模型
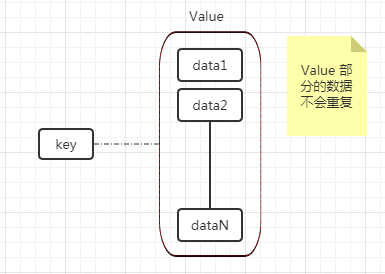
应用场景
set 类型的特点是——不重复且无序的一组数据,并且具有丰富的计算功能,在一些特定的场景中可以高效的解决一般关系型数据库不方便做的工作。
“共同好友列表”
社交类应用中,获取两个人或多个人的共同好友,两个人或多个人共同关注的微博这样类似的功能,用 MySQL 的话操作很复杂,可以把每个人的好友 id 存到集合中,获取共同好友的操作就可以简单到一个取交集的命令就搞定。
1 | // 这里为了方便阅读,把 id 替换成姓名 |
zset 数据类型的应用场景
简介
在 set 的基础上给集合中每个元素关联了一个分数,往有序集合中插入数据时会自动根据这个分数排序。
应用场景
在集合类型的场景上加入排序就是有序集合的应用场景了。比如根据好友的“亲密度”排序显示好友列表。
1 | // 用元素的分数(score)表示与好友的亲密度 |
文章标题:Redis 数据类型及应用场景
文章字数:2.1k
本文作者:Waterandair
发布时间:2018-08-11, 23:38:23
最后更新:2019-12-28, 14:03:59
原始链接:https://waterandair.github.io/2018-08-11-redis-basic.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

