Spark 的 Yarn-cluster 和 Yarn-client 提交模式
详细介绍 Spark on yarn 的两种不同运行模式的区别
Yarn-client 模式
说明
Yarn-client 模式用于测试, 因为 Driver 运行在本地客户端,负责调度 application, 会与 Yarn 集群产生大量的网络通信,从而导致网卡流量激增.
Yarn-client 模式的优点是可以在本地看到所有日志,方便调试
流程
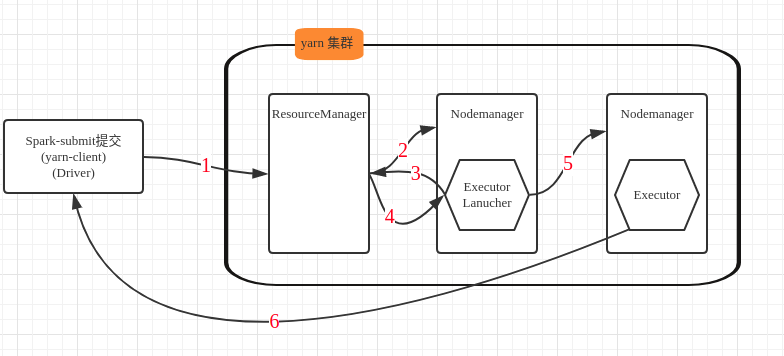
- spark-submit 本地提交 application, 在本地启动 Driver 进程, 发送请求到 ResourceManager, 请求启动 ApplicationMaster
- 分配一个 container, 在某个 Nodemanager 上启动一个 ExecutorLanucher(相当于 ApplicationMaster)
- ExecutorLanucher 向 ResourceManager 请求 Container, 启动 Executor
- ResourceManager 分配一批 container 用于启动 Executor
- ExecutorLanucher 连接到分配过来的 container(Nodemanager, 相当于Worker而), 启动 Executor
- Executor 启动后向本地 Driver 反向注册
Yarn-cluster 模式
说明
Yarn-cluster 模式用于生产环境,因为 Driver 运行在 nodemanager 上, 不会有网卡流量激增的问题.
Yarn-cluster 模式缺点是调试不方便,不能直接查看日志,需要使用 yarn logs -applicationId xxx 命令查看
流程
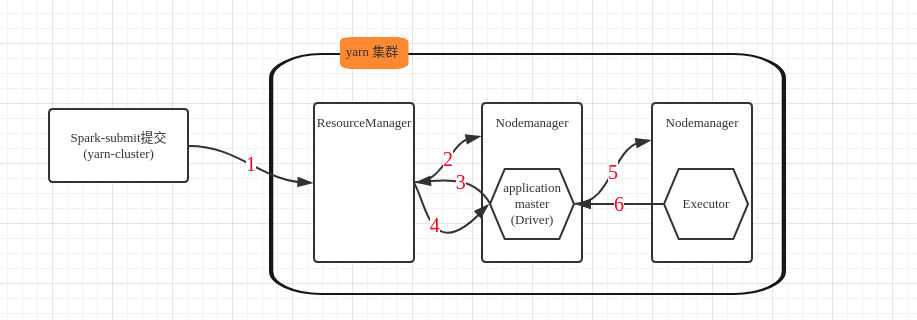
- spark-submit 本地提交 application, 发送请求到 ResourceManager, 请求启动 ApplicationMaster
- 分配一个 container, 在某个 Nodemanager 上启动 ApplicationMaster(相当于 Driver)
- ApplicationMaster 向 ResourceManager 请求 Container, 启动 Executor
- ResourceManager 分配一批 container 用于启动 Executor
- ApplicationMaster 连接到分配过来的 container(Nodemanager, 相当于Worker而), 启动 Executor
- Executor 启动后向 ApplicationMaster 反向注册
区别
Yarn-client 模式的 Driver 进程运行在提交 application 的本地, 而 Yarn-cluster 模式的 Driver 运行在 ApplicationMaster
配置注意
配置 Spark Yarn 模式 必须在 spark-env 文件中, 配置 HADOOP_CONF_DIR 或 或YARN_CONF_DIR属性, spark 会根据这个路径找打 hadoop 的配置,从而管理 Hdfs 和 Yarn
| 名称 | 默认值 | 含义 |
|---|---|---|
| spark.yarn.am.memory | 512m | client模式下,YARN Application Master使用的内存总量 |
| spark.yarn.am.cores | 1 | client模式下,Application Master使用的cpu数量 |
| spark.driver.cores | 1 | cluster模式下,driver使用的cpu core数量,driver与Application Master运行在一个进程中,所以也控制了Application Master的cpu数量 |
| spark.yarn.am.waitTime | 100s | cluster模式下,Application Master要等待SparkContext初始化的时长; client模式下,application master等待driver来连接它的时长 |
| spark.yarn.submit.file.replication | hdfs副本数 | 作业写到hdfs上的文件的副本数量,比如工程jar,依赖jar,配置文件等,最小一定是1 |
| spark.yarn.preserve.staging.files | false | 如果设置为true,那么在作业运行完之后,会避免工程jar等文件被删除掉 |
| spark.yarn.scheduler.heartbeat.interval-ms | 3000 | application master向resourcemanager发送心跳的间隔,单位ms |
| spark.yarn.scheduler.initial-allocation.interval | 200ms | application master在有pending住的container分配需求时,立即向resourcemanager发送心跳的间隔 |
| spark.yarn.max.executor.failures | executor数量*2,最小3 | 整个作业判定为失败之前,executor最大的失败次数 |
| spark.yarn.historyServer.address | 无 | spark history server的地址 |
| spark.yarn.dist.archives | 无 | 每个executor都要获取并放入工作目录的archive |
| spark.yarn.dist.files | 无 | 每个executor都要放入的工作目录的文件 |
| spark.executor.instances | 2 | 默认的executor数量 |
| spark.yarn.executor.memoryOverhead | executor内存10% | 每个executor的堆外内存大小,用来存放诸如常量字符串等东西 |
| spark.yarn.driver.memoryOverhead | driver内存7% | 同上 |
| spark.yarn.am.memoryOverhead | AM内存7% | 同上 |
| spark.yarn.am.port | 随机 | application master端口 |
| spark.yarn.jar | 无 | spark jar文件的位置 |
| spark.yarn.access.namenodes | 无 | spark作业能访问的hdfs namenode地址 |
| spark.yarn.containerLauncherMaxThreads | 25 | application master能用来启动executor container的最大线程数量 |
| spark.yarn.am.extraJavaOptions | 无 | application master的jvm参数 |
| spark.yarn.am.extraLibraryPath | 无 | application master的额外库路径 |
| spark.yarn.maxAppAttempts | 提交spark作业最大的尝试次数 | |
| spark.yarn.submit.waitAppCompletion | true | cluster模式下,client是否等到作业运行完再退出 |
查看日志
在yarn模式下,spark作业运行相关的executor和ApplicationMaster都是运行在yarn的container中的, 所以日志也是分散的, 有下面几种方式查看日志
聚合日志(推荐,常用)
这种方式将散落在集群中各个机器上的日志,最后都聚合起来,container的日志会拷贝到hdfs上去,并从机器中删除,方便统一查看.
开启:
开启日志聚合的选项,即 yarn.log-aggregation-enable,
查看:
使用 yarn logs -applicationId <app ID>命令查看日志
yarn logs命令,会打印出 application 对应的所有 container 的日志出来,因为日志是在hdfs上的,也可以通过hdfs的命令行来直接从hdfs中查看日志,日志在hdfs中的目录,可以通过查看yarn.nodemanager.remote-app-log-diryarn.nodemanager.remote-app-log-dir-suffix属性来获知
web ui 方式
需要启动History Server,让spark history server 和 mapreduce history server运行着,并且在yarn-site.xml文件中,配置yarn.log.server.url属性.
spark history server web ui中的log url,会重定向到mapreduce history server上去查看日志
分散查看(通常不推荐)
如果没有打开聚合日志选项,那么日志默认就是散落在各个机器上的本次磁盘目录中的,在YARN_APP_LOGS_DIR目录下,根据hadoop版本的不同,通常在/tmp/logs目录下,或者$HADOOP_HOME/logs/userlogs目录下
如果要查看某个container的日志,那么就得登录到那台机器上去,然后到指定的目录下去,找到那个日志文件,就才能查看.
启动
eg.
1 | spark-submit --master yarn-cluster \ |
文章标题:Spark 的 Yarn-cluster 和 Yarn-client 提交模式
文章字数:1.4k
本文作者:Waterandair
发布时间:2018-01-27, 09:24:06
最后更新:2019-12-28, 14:03:59
原始链接:https://waterandair.github.io/2018-01-27-spark-yarn-client-cluster.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

