kafka python 客户端使用
创建时间:2017-12-19 12:58
字数:1.5k
使用 kafka-python 做 kafka 生产者和消费者客户端开发, 安装方式: pip install kafka-python==1.4.2
基本概念
消费者(Consumer): 从消息队列中请求消息的客户端应用程序
生产者(Producer): 向 broker 发布消息的客户端应用程序
AMOP 服务器端(broker): 用来接收生产者发送的消息并将这些消息路由给服务器中的队列
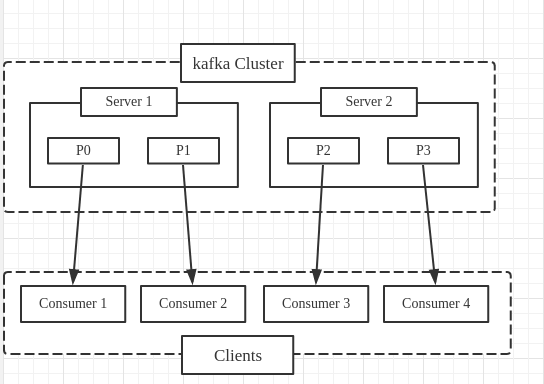
主题(Topic): 类似分类的概念,实际应用中,通常一个业务一个主题
分区(Partition): 一个 topic 中的消息数据按照多个分区组织,分区是 kafka 消息队列组织的最小单位,一个分区可以看做是一个 FIFO 的队列
kafka python客户端开发 (代码 ) 生产者编模型 同步生产
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #!/usr/bin/python3 # -*- coding utf-8 -*- from kafka import KafkaProducer from kafka.errors import KafkaError import msgpack import json """ bootstrap_servers: kafka 服务器地址 value_serializer: 指定用于序列化对象的方法 msgpack.dumps eg. producer = KafkaProducer(value_serializer=msgpack.dumps) producer.send('msgpack-topic', {'key': 'value'}) producer = KafkaProducer(value_serializer=lambda m: json.dumps(m).encode('ascii')) producer.send('json-topic', {'key': 'value'}) retries: 重试次数 acks: 服务器端返回响应的时机 0: 不需要返回响应 1: 服务器写入 local log 后返回响应 (默认) all: 消息提交到了集群中所有的副本后,返回响应 """ producer = KafkaProducer( bootstrap_servers=[ "172.17.0.2:9092", "172.17.0.3:9092", "172.17.0.4:9092", ], ) # key 用于hash, 相同 key 的 value 提交到相同的 partition,key 的值默认为 None, 表示随机分配 res = producer.send(topic='test', value=b'this is a sync test', key=None) # producer 默认是异步模式, 调用 send 函数返回对象的 get 方法,可以把异步模式转换为同步模式 try: record_metadata = res.get(timeout=10) # 获取成功返回响应的数据 print(record_metadata.topic) print(record_metadata.partition) print(record_metadata.offset) except KafkaError: # 处理异常 pass
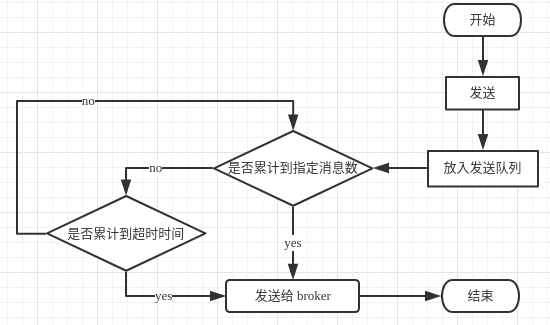
异步生产
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #!/usr/bin/python3 # -*- coding utf-8 -*- import time from kafka import KafkaProducer import msgpack import json """ bootstrap_servers: kafka 服务器地址 value_serializer: 指定用于序列化对象的方法 msgpack.dumps eg. producer = KafkaProducer(value_serializer=msgpack.dumps) producer.send('msgpack-topic', {'key': 'value'}) producer = KafkaProducer(value_serializer=lambda m: json.dumps(m).encode('ascii')) producer.send('json-topic', {'key': 'value'}) retries: 重试次数 acks: 服务器端返回响应的时机 0: 不需要返回响应 1: 服务器写入 local log 后返回响应 (默认) all: 消息提交到了集群中所有的副本后,返回响应 异步模式下,producer不会马上把消息发送到 kafka,而是根据触发条件一批一批的发送,batch_size 和 linger_ms 满足其一,就会提交消息 batch_size: 每一批消息累计的最大消息数, 默认 16384 linger_ms: 每一批消息最大累计时长 默认0 ms """ producer = KafkaProducer( bootstrap_servers=[ "172.17.0.2:9092", "172.17.0.3:9092", "172.17.0.4:9092", ], batch_size=5, linger_ms=3000 ) # key 用于hash, 相同 key 的 value 提交到相同的 partition,key 的值默认为 None, 表示随机分配 for i in range(100): mes = ('this is a async test ' + str(i)).encode() producer.send(topic='test', value=mes, key=None) time.sleep(1) # block until all async messages are sent producer.flush()
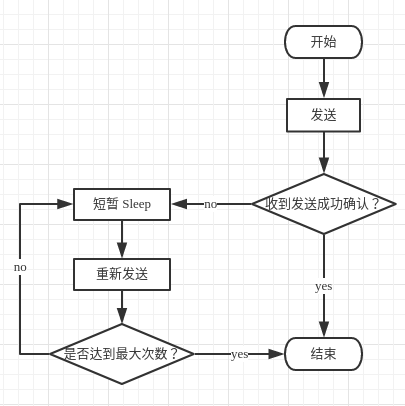
同步生产和异步生产的区别 同步生产:
低消息丢失率
高消息重复率(在未收到确认信息的情况下)
高延迟
异步生产:
低延迟
高发送性能
高消息丢失率(无确认机制,发送端队列满)
消费者编程模型
同一分组内的 consumer 共同消费指定的 topic, 如果一个分组内只有一个 consumer, 那么它会拿到 topic 的全部数据,如果有多个 consumer ,那么每个 consumer 拿到一部分 topic 数据
自动提交 offset 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #!/usr/bin/python3 # -*- coding utf-8 -*- from kafka import KafkaConsumer """ enable_auto_commit: 是否自动提交 offset 默认True auto_offset_commit: 当发生 OffsetOutOfRange 时, 重置 offset 的策略,默认 latest latest: 设置 offset 为最近一个消息,如果采用latest,消费者只能得道其启动后生产者生产的消息 earliest: 设置 offset 为存在的时间最长的一条消息 consumer_timeout_ms: 获取不到消息等待的时间,超过这个值,就会抛出 StopIteration 异常 """ consumer = KafkaConsumer( bootstrap_servers=[ '172.17.0.2:9092', '172.17.0.3:9092', '172.17.0.4:9092', ], group_id='group-1', enable_auto_commit=True, auto_offset_reset='earliest', consumer_timeout_ms=1000 ) consumer.subscribe(["test"]) while True: for message in consumer: print("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition, message.offset, message.key, message.value))
手动提交 offset 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #!/usr/bin/python3 # -*- coding utf-8 -*- from kafka import KafkaConsumer """ enable_auto_commit: 是否自动提交 offset 默认True auto_offset_commit: 当发生 OffsetOutOfRange 时, 重置 offset 的策略,默认 latest latest: 设置 offset 为最近一个消息,如果采用latest,消费者只能得道其启动后生产者生产的消息 earliest: 设置 offset 为存在的时间最长的一条消息 consumer_timeout_ms: 获取不到消息等待的时间,超过这个值,就会抛出 StopIteration 异常 """ consumer = KafkaConsumer( bootstrap_servers=[ '172.17.0.2:9092', '172.17.0.3:9092', '172.17.0.4:9092', ], group_id='group-3', enable_auto_commit=False, auto_offset_reset='earliest', consumer_timeout_ms=1000 ) consumer.subscribe(["test"]) size = 10 while True: records_list = [] for message in consumer: print("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition, message.offset, message.key, message.value)) records_list.append(message) if len(records_list) > size: # 集中处理这一批消息,处理成功后,再提交 offset, 实现了 at least once 的语义 # 异步提交 offset consumer.commit_async() # 清空 records_list records_list.clear()
手动提交 offset 和自动提交 offset 的区别 分区消费模型更加灵活:
需要自己处理各种异常情况
需要自己管理 offset(自己实现消息传递的语义,最少一次或最多一次)
组消费模型更加简单,但不灵活:
不需要自己处理异常情况,不需要自己管理offset
只能实现 kafka 默认的最多一次消息传递的语义
文章标题: kafka python 客户端使用
文章字数: 1.5k
本文作者: Waterandair
发布时间: 2017-12-19, 12:58:50
最后更新: 2019-12-28, 14:03:59
原始链接: https://waterandair.github.io/2017-12-19-kafka-intro.html
版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。