大数据的数据采集流程
大数据开发的数据来源基本介绍
离线数据采集
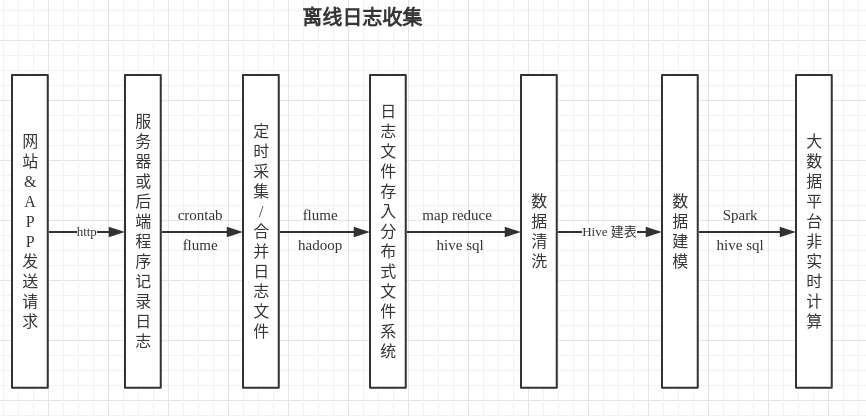
数据源
网站/APP向后台发送请求,获取数据,执行业务逻辑,都会经过服务器(nginx,apache,tomcat,jetty等),服务器会把每一次请求相关的信息,都保存起来,一般都是按照一定格式和命名规则保存到文件中.后台负责处理请求的代码(python,php,ruby,java等等),也会根据不同业务逻辑,按照一定格式记录特定的日志.
数据采集
几乎所有的互联网公司后端都不会只有一台服务器了,所以,每天生成的日志文件,会分布在多台服务器上,这时候,就需要用一个分布式的日志收集工具把日志定时收集到分布式存储系统(HDFS)上.简单来说,就是每天凌晨(或其他时间)把当天或前一天生成的日志文件,转移到flume监听的目录下, flume 在根据 sink 的配置进行后续转移,通常 sink 都设置为 HDFS
数据清洗
原始日志文件存储在 HDFS 中后,可能会有一些数据是不符合预期的脏数据,在进行正式的大数据计算之前,通常都需要执行一些 MapReduce 操作,或 hive sql 操作进行数据清洗
数据建模
日志文件中包含全部的信息,但是后续执行的特定业务场景的计算并不需要全部的数据,所以要将日志文件这个原始表,转换为符合特定业务场景的数据仓库,可能转换为几十张表,也可能是几百张
大数据平台计算
Spark 的数据来源,通常都是符合特定需求的 Hive 表, spark 利用 hive 中的数据源,提供快速的,符合业务需求的大数据计算和分析
实时数据采集
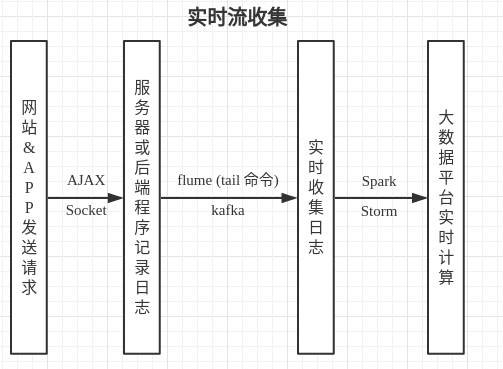
数据源
和离线日志收集类似,实时数据的数据源也来自用户在各个平台上发送的请求,不同的一点时,实时流也有很多是通过”点击流”获取的.
后端接收并处理请求
所谓点击流,举个例子,比如在网页中加入特定的ajax,用户执行某个点击操作的同时,向后端发送 ajax 请求,后端接收到请求之后,直接发送给 kafka 等消息队列,或者也可以写到 flume 监听的文件(使用tail命令监听的方式,可以监听到日志文件内容每一次的增加)或目录中
实时收集日志
实时数据,通常都是从分布式消息队列中读取的,比如 kafka
大数据平台实时处理数据
Storm(毫秒级),Spark streaming(秒级)等系统可以实时的从 kafka 中获取数据,然后对数据进行处理和计算,比如不同维度实时的访问量,甚至一些复杂的机器学习,数据挖掘,实时推荐等.
文章标题:大数据的数据采集流程
文章字数:778
本文作者:Waterandair
发布时间:2017-10-06, 21:49:02
最后更新:2019-12-28, 14:03:59
原始链接:https://waterandair.github.io/2017-10-06-big-data-collect.html版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

