LinearRegression建立广告投放与销售量的模型(sklearn)
创建时间:
字数:704
使用 sklearn 中的线性模型建立关于广告投放与销售量的模型,帮助广告主合理投放广告.
源码
前三列表示在不同平台的投放量,最后一列表示产品的销售量
1
2
3
4
5
6
7
| ,TV,Radio,Newspaper,Sales
1,230.1,37.8,69.2,22.1
2,44.5,39.3,45.1,10.4
3,17.2,45.9,69.3,9.3
4,151.5,41.3,58.5,18.5
....
|
读取数据
1
2
3
4
| path = "../data/advertising.csv"
data = pd.read_csv(path)
x = data[['TV', 'Radio', 'Newspaper']]
y = data['Sales']
|
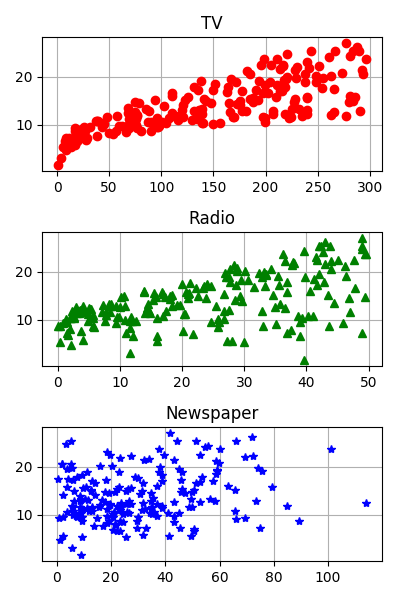
绘图查看数据
绘制三张图,分别是每种媒体平台投放量x与销售额y的散点图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| plt.figure(figsize=(4, 6))
# 子图, 子图规格, 三位[1, 3]的整数,
# 第一个数表示共有几个子图,
# 第二个数表示每行显示几个子图,
# 第三个数表示现在绘制的是第几个子图
plt.subplot(311)
plt.plot(data['TV'], y, 'ro')
plt.title('TV')
plt.grid()
plt.subplot(312)
plt.plot(data['Radio'], y, 'g^')
plt.title('Radio')
plt.grid()
plt.subplot(313)
plt.plot(data['Newspaper'], y, 'b*')
plt.title('Newspaper')
plt.grid()
plt.tight_layout() # 自动调整子图参数
plt.show()
|
训练模型
这个问题属于回归问题,所以选择线性回归,能用简单模型解决的问题,就不需要复杂的模型,复杂模型会增加不确定性,增加成本,且容易过拟合
样本数据共有200条,设置test_size=0.25的意思是从样本中取50条数据为测试数据,150条数据为训练数据
1
2
3
4
5
6
| x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, random_state=1)
linearReg = LinearRegression()
model = linearReg.fit(x_train, y_train)
print(model)
print(linearReg.coef_) # 估计系数
print(linearReg.intercept_) # 独立项/截距
|
测试模型
1
2
3
4
| y_hat = linearReg.predict(x_test)
mse = np.average((y_hat - np.array(y_test)) ** 2) # 均方误差
rmse = np.sqrt(mse) # 均方根误差
print(mse, rmse)
|
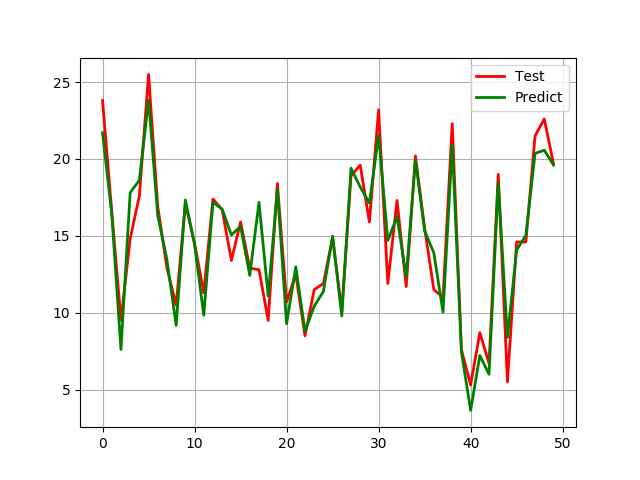
绘图对比预测结果与真实值的差异
1
2
3
4
5
6
| t = np.arange(len(x_test))
plt.plot(t, y_test, 'r-', linewidth=2, label='Test') # 红色折线图
plt.plot(t, y_hat, 'g-', linewidth=2, label='Predict') # 绿色折线图
plt.legend(loc='upper right')
plt.grid()
plt.show()
|
使用交叉验证的方式建立Lasso和Ridge模型(源码)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1)
# model = Lasso()
model = Ridge()
alpha = np.logspace(-3, 2, 10) # 取一个等差数列, 数列中的数作为超参数
liner_model = GridSearchCV(model, param_grid={'alpha': alpha}, cv=5) # 训练数据分成5份做交叉验证
liner_model.fit(x_train, y_train)
print("超参数:", liner_model.best_params_)
y_hat = liner_model.predict(np.array(x_test))
mse = np.average((y_hat - np.array(y_test)) ** 2)
rmse = np.sqrt(mse)
print("均方误差", mse, "均方根误差", rmse)
print("分数", liner_model.score(x_test, y_test))
print(liner_model.best_score_)
|
文章标题:LinearRegression建立广告投放与销售量的模型(sklearn)
文章字数:704
本文作者:Waterandair
发布时间:2018-03-10, 09:24:06
最后更新:2019-12-28, 14:03:59
原始链接:https://waterandair.github.io/2018-03-10-ml-linearregression-advertising.html
版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

