手写python代码介绍各种 RPC 模型, 代码地址
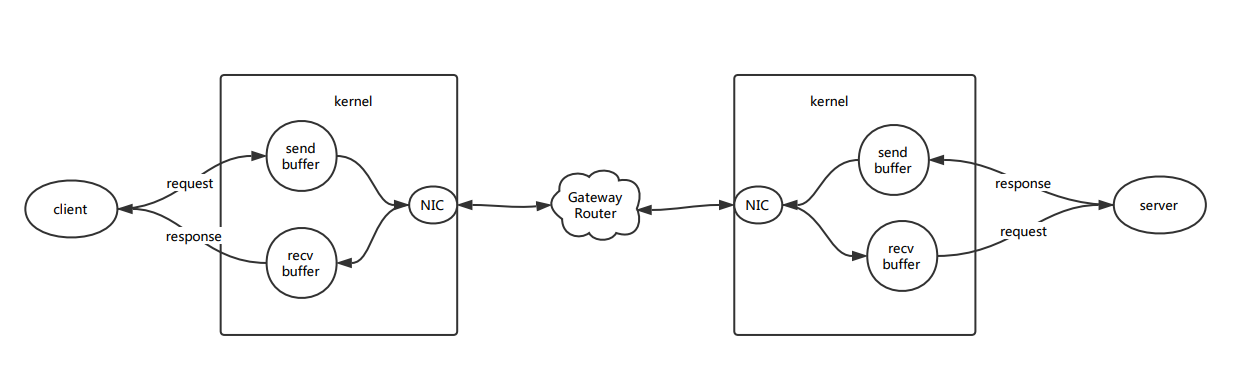
什么是RPC RPC(Remote Procedure Call)即远程过程调用,用于解决分布式系统的通信问题,常见的所有基于 TCP 协议的通信方式都可以看做是一种RPC, 比如http也是一种特殊的RPC, 但通常所说的 RPC 指的是长连接交互.客户端(clien)和服务器端(server)通过 文件描述符 的读写API访问操作系统内核中的网络模块,在当前套接字(socket)上按照规定好的格式发送(send buffer) 和接收缓存 (recv buffer)来完成数据的传输.RPC可以理解为是对底层通信和交互协议的一个封装.
RPC 的一般过程
server 端监听本地端口,等待客户端连接
客户端连接server端
客户端发出请求,等待服务端响应
服务端接收到客户端发送的请求,处理后返回响应
客户端接收到服务器发送过来响应
客户端关闭连接
最简单的代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # server.py import socket def main(): sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 打开一个ipv4的tcp套接字 sock.bind(("localhost", 8083)) sock.listen(1) # server 端监听本地端口,等待客户端连接 try: while True: conn, addr = sock.accept() # 接收一个客户端连接 print(conn.recv(1024)) # 从 recv buffer中读取消息, 服务端接收到客户端发送的请求,处理后返回响应 conn.sendall(b"pong") # 将响应发送到 send buffer conn.close() except KeyboardInterrupt: sock.close() if __name__ == '__main__': main()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # client import socket def main(): sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.connect(("localhost", 8083)) # 客户端连接server端 sock.sendall(b"ping") # 将消息发送到 send buffer, 客户端发出请求,等待服务端响应 print(sock.recv(1024)) # 从 recv buffer 中读取响应, 客户端接收到服务器发送过来响应 sock.close() # 客户端关闭连接 if __name__ == '__main__': main()
RPC 客户端 消息协议 的边界使用长度前缀法,使用一个4字节的二进制字符串表示消息体的长度,消息体使用 json 格式进行序列化和发序列化
消息的结构规定为下:
1 2 3 4 5 6 7 8 9 10 11 # 请求 { in: "ping", params: "0" } # 响应 { out: "pong" result: "0" }
客户端代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #!/usr/bin/ python3 # -*- coding: utf-8 -*- """rpc客户端""" import json import time import struct import socket def rpc(sock, in_, params): # 根据协议构造请求 request = json.dumps({"in": in_, "params": params}) # 序列化请求消息体 length_prefix = struct.pack("I", len(request)) # 请求长度前缀, 将一个整数编码成 4 个字节的字符串, "I" 表示无符号的整数 sock.send(length_prefix) sock.sendall(request.encode()) # sendall 会执行 flush # 根据协议解析响应 res_length_prefix = sock.recv(4) # 接收响应长度前缀 length, = struct.unpack("I", res_length_prefix) body = sock.recv(length) # 接收指定长度的响应消息体 response = json.loads(body.decode()) return response["out"], response["result"] # 返回响应类型和结果 if __name__ == '__main__': s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect(("localhost", 8080)) addr, port = s.getsockname() print(addr, port) # 打印出客户端的地址和占用的端口 # 连续发送10个请求 for i in range(10): out, result = rpc(s, "ping", "hello {}".format(i)) print(out, result) time.sleep(1) s.close()
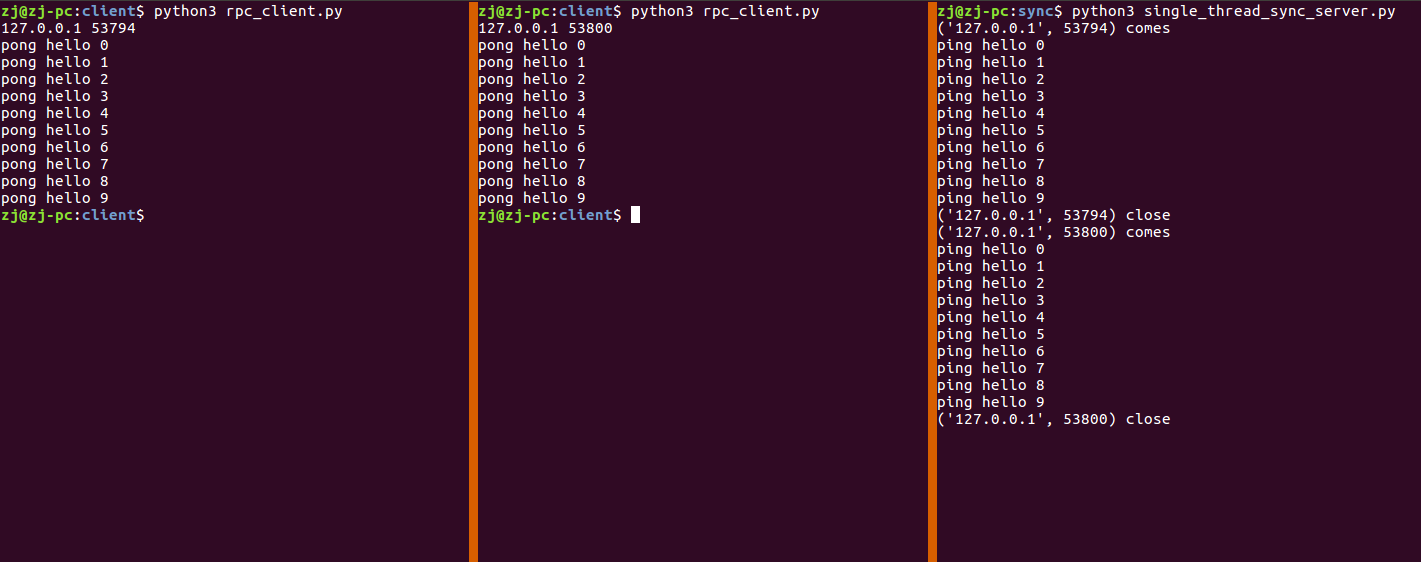
RPC 服务端 同步模型 单线程同步模型 单线程同步模型一次只能处理一个连接,这个请求处理完毕并关闭连接后,才能再处理下一个连接.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 #!/usr/bin/ python3 # -*- coding: utf-8 -*- """单线程同步模型rpc服务器""" import json import struct import socket def handle_conn(conn, addr, handlers): """接收并处理请求""" print(addr, "comes") # 循环读写 while True: length_prefix = conn.recv(4) # 接收4个字节的请求长度 if not length_prefix: # 连接关闭了 print(addr, "close") conn.close() break # 退出循环,处理下一个连接 length, = struct.unpack("I", length_prefix) body = conn.recv(length) # 根据接收到的消息体的长度接收请求消息体 request = json.loads(body.decode()) in_ = request["in"] params = request["params"] print(in_, params) handler = handlers[in_] # 找到响应的handler handler(conn, params) def ping(conn, params): send_result(conn, "pong", params) def send_result(conn, out, result): """发送消息体""" response = json.dumps({"out": out, "result": result}) # 构造响应消息体 length_prefix = struct.pack("I", len(response)) # 编码响应长度前缀 conn.send(length_prefix) conn.sendall(response.encode()) # sendall() 会执行 flush def loop(sock, handlers): """循环接收请求""" while True: conn, addr = sock.accept() # 接收连接 handle_conn(conn, addr, handlers) # 单线程处理请求,处理中会阻塞其它请求 if __name__ == '__main__': sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 创建一个基于 ipv4 的 TCP 套接字 sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) # 在套接字级别打开 SO_REUSEADDR sock.bind(("localhost", 8080)) sock.listen(1) # 监听客户端连接 # 注册请求处理器, 这里只用ping服务做演示 handlers = { "ping": ping } loop(sock, handlers)
如图所示,同时启动两个客户端,服务器端只能先处理完第一个连接,第一个连接关闭后,在处理第二个
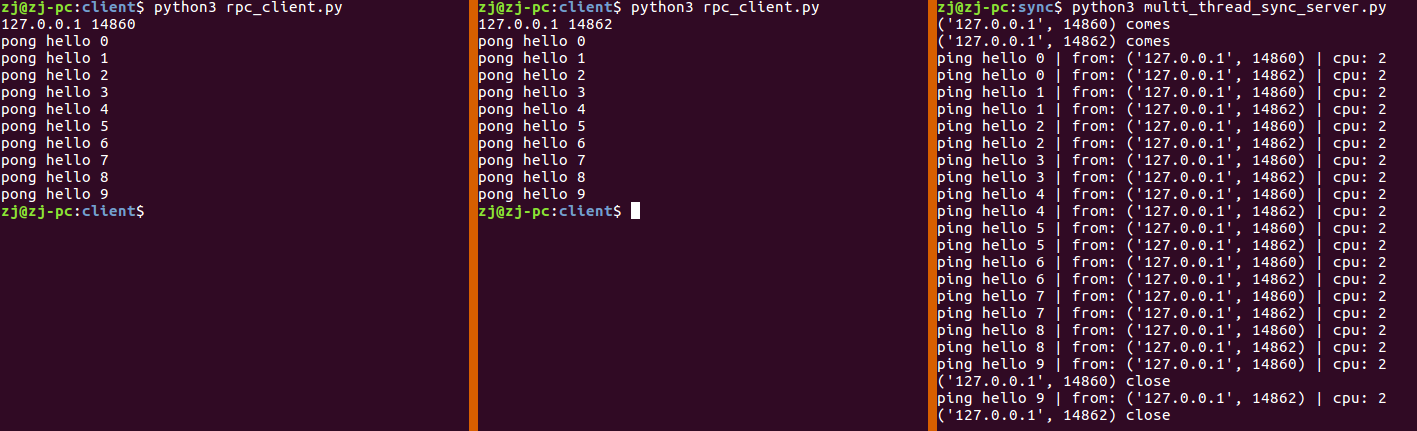
多线程同步模型 相比较单线程同步模型,仅仅修改了 loop 函数, 对每个连接新开一个线程进行处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 #!/usr/bin/ python3 # -*- coding: utf-8 -*- """多线程同步模型rpc服务器""" import json import struct import socket from threading import Thread def handle_conn(conn, addr, handlers): """接收并处理请求""" print(addr, "comes") # 循环读写 while True: length_prefix = conn.recv(4) # 接收请求长度 if not length_prefix: # 连接关闭了 print(addr, "close") conn.close() break # 退出循环,处理下一个连接 length, = struct.unpack("I", length_prefix) body = conn.recv(length) # 接收请求消息体 request = json.loads(body.decode()) in_ = request["in"] params = request["params"] # 获取当前运行程序的CPU核 res = os.popen('ps -o psr -p' + str(os.getpid())) cpu_id = res.readlines()[1].rstrip("\n").strip() print(in_, params, "|", "from:", addr, "|", "cpu: " + cpu_id) handler = handlers[in_] # 找到请求处理器 handler(conn, params) def send_result(conn, out, result): """发送消息体""" response = json.dumps({"out": out, "result": result}) # 构造响应消息体 length_prefix = struct.pack("I", len(response)) # 编码响应长度前缀 conn.send(length_prefix) conn.sendall(response.encode()) # sendall() 会执行 flush def ping(conn, params): send_result(conn, "pong", params) def loop(sock, handlers): """循环接收请求""" while True: conn, addr = sock.accept() # 接收连接 t = Thread(target=handle_conn, args=(conn, addr, handlers)) # 每接收一个新的请求,就会在一个新的线程中处理请求 t.start() if __name__ == '__main__': sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 创建一个基于 ipv4 的 TCP 套接字 sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) # 在套接字级别打开 SO_REUSEADDR sock.bind(("localhost", 8080)) sock.listen(1) # 监听客户端连接 # 注册请求处理器 handlers = { "ping": ping } # 进入服务循环 loop(sock, handlers)
从实验中可以看出,前后打开了两个客户端,服务器端不需要等待第一个客户端连接关闭,就可以处理第二个客户端连接.
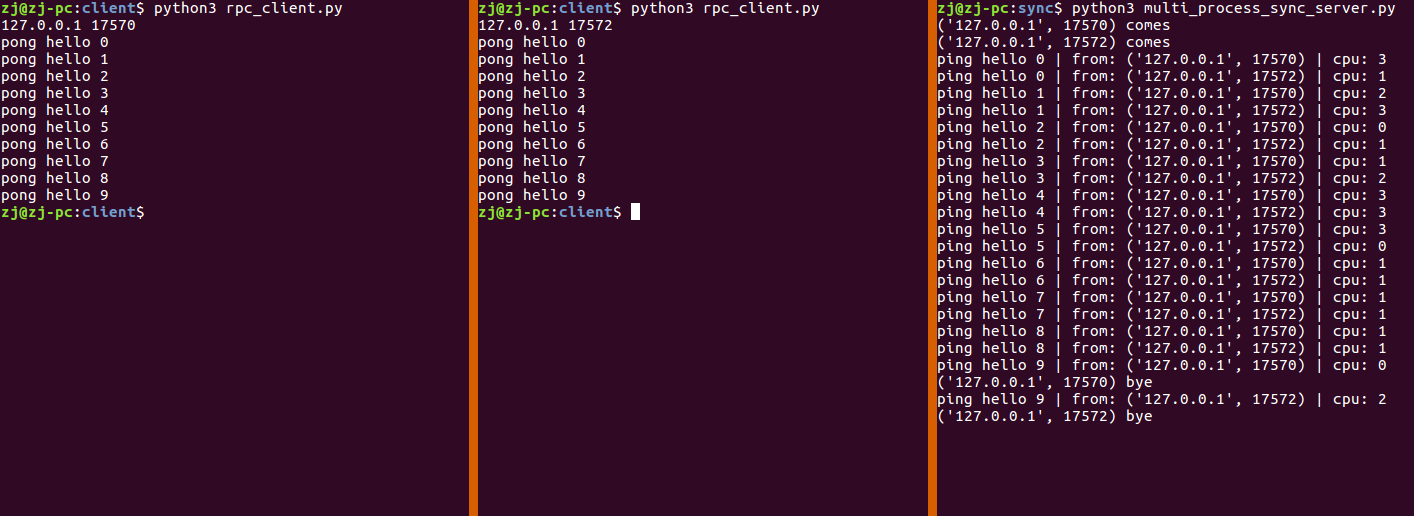
多进程同步模型 Python 的 GIL 导致单个进程只能占满一个 CPU 核心,导致多线程并不能充分利用多核的优势,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 #!/usr/bin/ python3 # -*- coding: utf-8 -*- """多进程同步模型""" import os import json import struct import socket import multiprocessing def loop_multiprocessing(sock, handlers): """使用 multiprocessing 的方式为每一个连接创建一个新的进程进行处理""" while True: conn, addr = sock.accept() p = multiprocessing.Process(target=handler_conn, args=(conn, addr, handlers)) p.start() def loop_fork(sock, handlers): """使用fork的方式为每一个连接创建一个新的进程进行处理""" """ 子进程和父进程的关系: 子进程创建后,父进程拥有的很多操作系统资源,会复制一份给子进程,比如套接字和文件描述符,它们本质上都是对操作系统内核对象的一个引用。 如果子进程不需要某些引用,一定要即时关闭它,避免操作系统资源得不到释放导致资源泄露。 进程 fork 之后,套接字会复制一份套接字连接到子进程,这时父子进程将会各有自己的套接字引用指向内核的同一份套接字对象。 在子进程里对套接字进程 close,并不是关闭套接字,其本质上只是将内核套接字对象的引用计数减一,只有当引用计数减为零时,才会关闭套接字. 所以关闭子进程的套接字后,要在父进程里也关闭客户端的套接字。 否则就会导致服务器套接字引用计数不断增长,同时客户端套接字对象也得不到即时回收,造成资源泄露。 """ while True: conn, addr = sock.accept() pid = os.fork() # fork 出一个子进程 if pid < 0: # 如果 fork 返回值小于零,一般意味着操作系统资源不足,无法创建进程。 return elif pid > 0: # fork在父进程的返回结果是一个大于0的整数值,这个值是子进程的进程号,父进程可以使用该进程号来控制子进程 conn.close() # 关闭父进程的客户端套接字,因为子进程已经复制了一份到子进程 continue else: # fork 在子进程的返回结果是零 sock.close() # 关闭子进程的服务器套接字, 因为只需要父进程保持套接字的监听 handler_conn(conn, addr, handlers) break # 处理完后一定要退出循环,不然子进程也会继续去 accept 连接 def handler_conn(conn, addr, handlers): print(addr, "comes") while True: length_prefix = conn.recv(4) if not length_prefix: print(addr, "bye") conn.close() break length, = struct.unpack("I", length_prefix) body = conn.recv(length).decode() request = json.loads(body) in_ = request["in"] params = request["params"] # 获取当前运行程序的CPU核 res = os.popen('ps -o psr -p' + str(os.getpid())) cpu_id = res.readlines()[1].rstrip("\n").strip() print(in_, params, "|", "from:", addr, "|", "cpu: " + cpu_id) handler = handlers[in_] handler(conn, params) def ping(conn, params): send_result(conn, "pong", params) def send_result(conn, out, result): response = json.dumps({"out": out, "result": result}).encode() length_prefix = struct.pack("I", len(response)) conn.send(length_prefix) conn.sendall(response) if __name__ == '__main__': sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) sock.bind(("localhost", 8080)) sock.listen(1) handlers = { "ping": ping } # loop_multiprocessing(sock, handlers) # python中提供了multiprocessing库去方面的进行多线程编程,这里使用fork是为了方便理解多进程 loop_fork(sock, handlers)
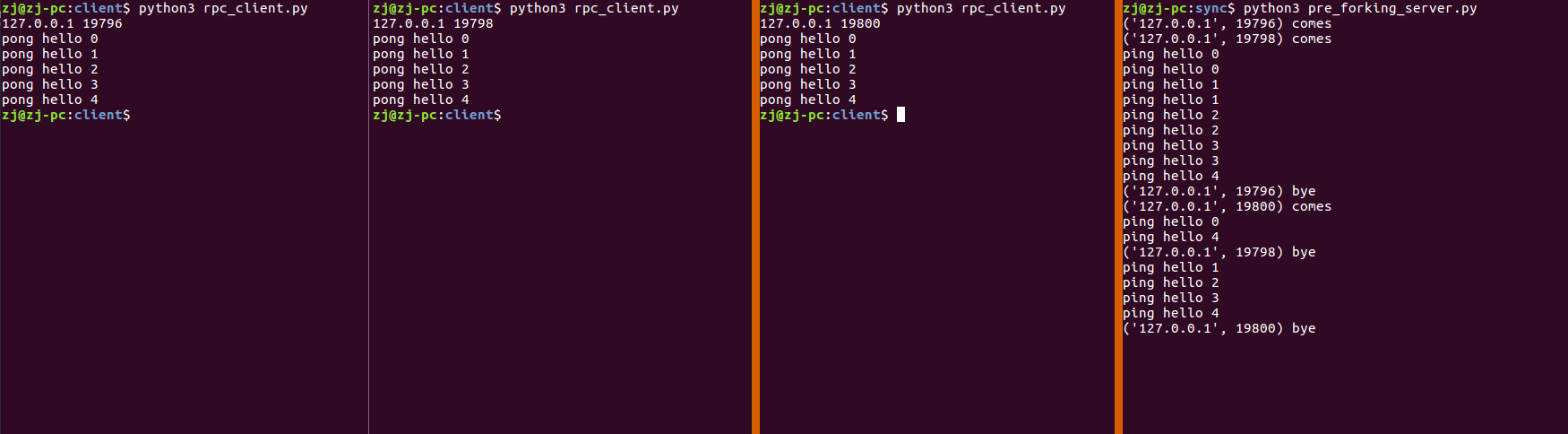
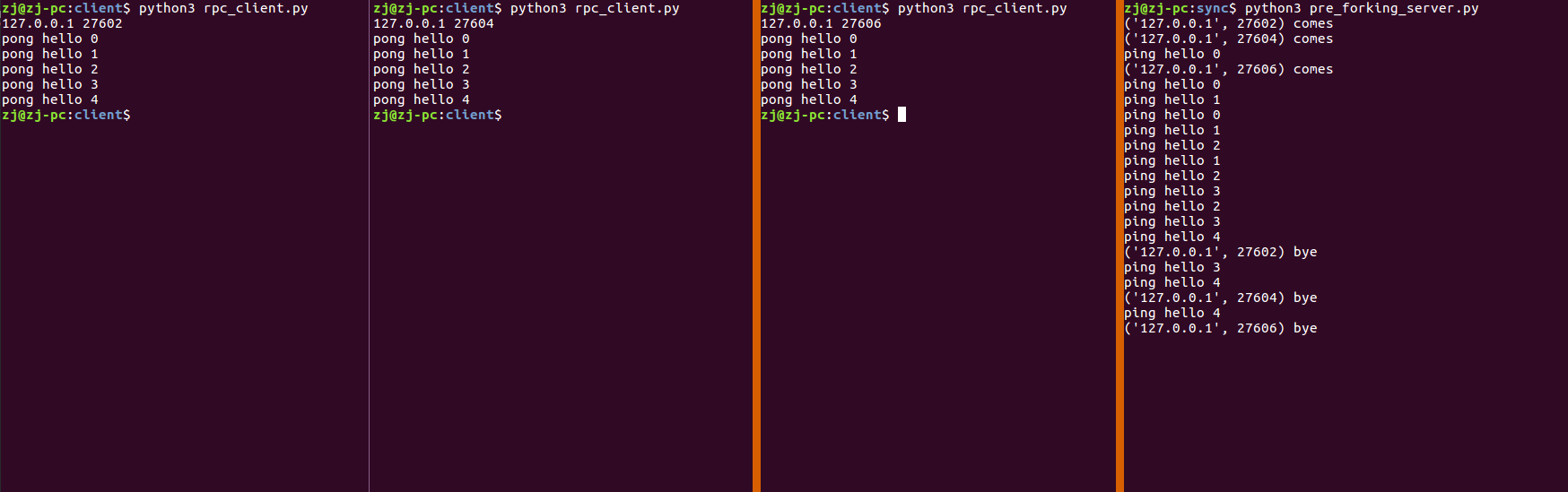
Preforking 同步模型 python多进程虽然可以使用到多核,但是由于进程比进程要消耗更多的资源,所以操作系统可以运行的进程的数量是相当有限的.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 #!/usr/bin/ python3 # -*- coding: utf-8 -*- """preforking 同步模型""" import os import json import struct import socket from threading import Thread def prefork(nums): """预先创建指定数量的子进程""" for i in range(nums): pid = os.fork() if pid < 0: return elif pid > 0: continue # 父进程继续循环,继续fork子进程 else: # pid == 0 break # 子进程退出循环处理请求 def ping(conn, params): send_result(conn, "pong", params) def send_result(conn, out, result): response = json.dumps({"out": out, "result": result}).encode() length_prefix = struct.pack("I", len(response)) conn.send(length_prefix) conn.sendall(response) def loop(sock, handlers): while True: conn, addr = sock.accept() handle_conn(conn, addr, handlers) # Thread(handle_conn, args=(conn, addr, handlers)) def handle_conn(conn, addr, hanlers): print(addr, "comes") while True: length_prefix = conn.recv(4) if not length_prefix: print(addr, "bye") break length, = struct.unpack("I", length_prefix) body = conn.recv(length).decode() request = json.loads(body) in_ = request["in"] params = request["params"] print(in_, params) handler = handlers[in_] handler(conn, params) if __name__ == '__main__': sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) sock.bind(("localhost", 8080)) sock.listen(1) # 开启 10个 子进程 # prefork(10) prefork(1) handlers = { "ping": ping } loop(sock, handlers)
在实验中,为了方面演示,只创建一个子进程,且只有一个线程,当主进程fork完子进程后,也会去处理请求,这样就相当于只有两个进程可以处理请求,当我依次打开三个客户端,可以看到第三个客户端一开始无法建立连接,当第一个客户端关闭连接后,才建立了连接.
在下面的试验中,在进程中使用多线程的方式处理请求,就可以处理大于进程数的请求了.
修改 loop 函数:
1 2 3 4 5 def loop(sock, handlers): while True: conn, addr = sock.accept() # handle_conn(conn, addr, handlers) Thread(handle_conn, args=(conn, addr, handlers))
异步模型 前面演示的都是同步模型,同步模型在读写数据的时候,如果数据没有就绪,就会阻塞当前线程,这种方式对操作系统资源是一种浪费,所以引进了非阻塞I/O模型,当前线程没有读写数据的时候,线程可以去做其他工作,当有数据需要读写的时候,再进行数据读写操作.
为了让线程知道何时可以进行读写数据的操作,操作系统提供了事件轮询的机制,比如apache使用的select机制和nginx使用的 epoll 机制.
单进程异步模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 #!/usr/bin/ python3 # -*- coding: utf-8 -*- """ 单线程异步 RPC 服务器模型 使用 asyncore 包实现 (select 多路复用系统调用)""" import asyncore from io import BytesIO import socket import json import struct class RPCServer(asyncore.dispatcher): """服务器套接字处理器必须继承dispatcher""" def __init__(self, host, port): asyncore.dispatcher.__init__(self) self.create_socket(socket.AF_INET, socket.SOCK_STREAM) self.set_reuse_addr() self.bind((host, port)) self.listen(1) def handle_accept(self): pair = self.accept() if pair is not None: sock, addr = pair PRCHandler(sock, addr) class PRCHandler(asyncore.dispatcher_with_send): """ 客户端套接字处理器必须继承 dispatcher_with_send """ def __init__(self, sock, addr): asyncore.dispatcher_with_send.__init__(self, sock=sock) self.addr = addr self.handlers = { "ping": self.ping } # 因为是非阻塞的,所以可能一条消息经历了多次读取,所以这里用一个BytesIO缓冲区存放读取进来的数据 self.rbuf = BytesIO() # 读缓冲区由用户代码维护,写缓冲区由 asyncore 内部提供 def ping(self, params): self.send_result("pong", params) def send_result(self, out, result): response = {"out": out, "result": result} body = json.dumps(response).encode() length_prefix = struct.pack("I", len(body)) self.send(length_prefix) self.send(body) def handle_connect(self): """新的连接被accept 回调方法""" print(self.addr, 'comes') def handle_close(self): """连接关闭之前回调方法""" print(self.addr, 'bye') self.close() def handle_read(self): """有读事件到来时回调方法""" while True: content = self.recv(1024) if content: self.rbuf.write(content) # 最后一部分数据,读取后退出循环 if len(content) < 1024: break self.handle_rpc() def handle_rpc(self): """将读到的消息解包并处理""" while True: # 可能一次性收到了多个请求消息,所以需要循环处理 self.rbuf.seek(0) length_prefix = self.rbuf.read(4) if len(length_prefix) < 4: # 不足一个消息 break length, = struct.unpack("I", length_prefix) body = self.rbuf.read(length) if len(body) < length: # 不足一个消息 break request = json.loads(body.decode()) in_ = request['in'] params = request['params'] print(in_, params) handler = self.handlers[in_] handler(params) # 处理消息 left = self.rbuf.getvalue()[length + 4:] # 消息处理完了,缓冲区要截断 self.rbuf = BytesIO() self.rbuf.write(left) self.rbuf.seek(0, 2) # 将游标挪到文件结尾,以便后续读到的内容直接追加 if __name__ == '__main__': RPCServer("localhost", 8080) asyncore.loop()
Preforking 异步模型 和单进程同步模型一样,受 Python GIL 的影响,单进程异步模型也只能使用一个CPU,为了利用好多核,可以改用 Preforking 的异步模式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 #!/usr/bin/ python3 # -*- coding: utf-8 -*- """PerForking 异步 RPC 服务器""" import os import json import struct import socket import asyncore from io import BytesIO class RPCServer(asyncore.dispatcher): def __init__(self, host, port): asyncore.dispatcher.__init__(self) self.create_socket(socket.AF_INET, socket.SOCK_STREAM) self.set_reuse_addr() self.bind((host, port)) self.listen(1) self.prefork(10) # 创建10个子进程 def prefork(self, n): for i in range(n): pid = os.fork() if pid < 0: # fork error return if pid > 0: # 父进程 continue if pid == 0: break # 子进程 def handle_accept(self): # 获取连接 pair = self.accept() if pair is not None: sock, addr = pair # 处理连接 RPCHandler(sock, addr) class RPCHandler(asyncore.dispatcher_with_send): def __init__(self, sock, addr): asyncore.dispatcher_with_send.__init__(self, sock=sock) self.addr = addr self.handlers = { "ping": self.ping } # 因为是非阻塞的,所以可能一条消息经历了多次读取,所以这里用一个BytesIO缓冲区存放读取进来的数据 self.rbuf = BytesIO() def handle_connect(self): print(self.addr, "comes") def handle_close(self): print(self.addr, "bye") self.close() def handle_read(self): while True: content = self.recv(1024) if content: # 追加到读缓冲 self.rbuf.write(content) # 说明内核缓冲区空了,等待下个事件循环再继续读 if len(content) < 1024: break self.handle_rpc() def handle_rpc(self): while True: self.rbuf.seek(0) length_prefix = self.rbuf.read(4) if len(length_prefix) < 4: break length, = struct.unpack("I", length_prefix) body = self.rbuf.read(length) if len(body) < length: break request = json.loads(body.decode()) in_ = request['in'] params = request['params'] print(os.getpid(), in_, params) handler = self.handlers[in_] handler(params) # 截断读缓冲 left = self.rbuf.getvalue()[length + 4:] self.rbuf = BytesIO() self.rbuf.write(left) self.rbuf.seek(0, 2) # 移动游标到缓冲区末尾,便于后续内容直接追加 def ping(self, params): self.send_result("pong", params) def send_result(self, out, result): response = {"out": out, "result": result} body = json.dumps(response) length_prefix = struct.pack("I", len(body)) self.send(length_prefix) self.send(body.encode()) if __name__ == '__main__': RPCServer("localhost", 8080) # 进入事件循环 asyncore.loop()